
Data Mesh: qué es, ventajas y cómo implementar esta arquitectura de datos

Uno de los problemas más recurrentes que se encuentra una organización que invierte en la gestión del big data es cómo responden los diferentes equipos a la búsqueda y obtención de información dentro de los almacenes de datos dispuestos, sin que ello suponga sobrecargar a IT. De esta premisa parte la naturaleza del término Data Mesh, que de forma muy resumida supone “la democratización de los datos”: ofrecer a cualquiera de los usuarios de la información de empresa su acceso de forma rápida, así como una colaboración entre equipos más fluida.
En el siguiente artículo definiremos el término, diferenciándolos de otros conceptos similares e indicando cómo y cuándo conviene implementarlo, incidiendo sobre todo en los problemas que resuelve en el día a día de una empresa a la hora de trabajar con sus propios datos.
¿Qué es Data mesh?
Un primer acercamiento al término data mesh sería el uso de un enfoque centrado en los usuarios y en el producto a la hora de obtener información de fuentes de datos numerosas y heterogéneas, o de forma más técnica, el término que se ha adoptado para el proceso de descentralización de datos analíticos en un entorno big data dentro de una organización, con la finalidad de que cualquiera dentro de la estructura de la empresa, pueda compartir, acceder y gestionar la información de forma independiente y sin afectar al resto de la organización.
Todo ello supone un cambio en el tradicional rol que la gestión del dato había tenido hasta ahora en las organizaciones, donde los “dueños de los datos” residen en una parte de la empresa (normalmente ingenieros de datos o data scientists) para controlarlos y solo hacerlos accesibles al resto mediante la creación de data lakes o data warehouses.
“Acceso a datos más rápidamente y colaboración sencilla entre equipos en la era big data: los dos factores clave que persigue el Data Mesh”
Así, el data mesh lo que permite es la construcción de una infraestructura de autoservicio que valida a cualquier equipo (sea técnico o no) utilizar recursos y herramientas bajo demanda, para acceder a los datos correctos, procesarlos, prepararlos y analizarlos sin necesidad de formación previa o conocimiento de cómo se han producido.
 |
El término Data Mesh (malla de datos), fue introducido por primera vez en 2019, mediante la ingeniera, arquitecta de software, emprendedora y especialista en datos, Zhamak Dehghani a través de su artículo “Cómo pasar de un data lake monolítico a una malla de datos distribuida”. En él proponía un cambio de paradigma en el tratamiento de los datos a través de la enumeración de las características que debería tener una plataforma de datos moderna. Estas características formarían la naturaleza de lo que hoy conocemos como Data Mesh. |
Problemáticas que resuelve el uso de Data Mesh
Invertimos en gestión del big data porque nos damos cuenta de que el valor de los datos se pierde a medida que crece su tamaño si no se canaliza adecuadamente. Pero esa canalización, que llevamos a cabo mediante el uso de herramientas y la creación de equipos profesionales del dato, requiere de altos conocimientos técnicos y una alta disposición a resolver diferentes cuestiones, de diferente naturaleza y proveniente de diferentes fuentes.
Este hecho crea la paradoja de que la solución a una saturación de flujos de datos, pasa por una saturación del equipo técnico que los gestiona, que no solo se ven inmersos en la ya costosa a nivel de tiempo de dedicación, tarea de reparar canalizaciones de datos rotas, sino que también se deben preocupar de atender a las diferentes peticiones de información provenientes de diferentes departamentos, cada uno con unas necesidades diferentes y un lenguaje a la hora de trabajar los datos también heterogéneo. Peticiones que incluso se pueden llegar a cruzar e involucrar a diferentes estamentos de la empresa.
Es lo que ocurre por ejemplo con casos cotidianos en una empresa de venta de retail, la cual puede tener los deberes bien hechos a la hora de tener toda la información de productos, clientes y transacciones bien organizada y clasificada dentro de cada departamento implicado, pero que a la hora de responder a cuestiones interdepartamentales, la fluidez de la información se limita.
Así, el fin máximo (la calidad del dato) no se verá comprometido, pero sí la velocidad, la agilidad y la practicidad del tratamiento al encontrarse plenamente centralizada. Es este “el punto débil” de la gestión big data que aborda Data Mesh, resolviéndolo de la forma más evidente posible: si el problema viene de un dato centralizado, la solución viene de descentralizarlo.

Cómo facilitar la fluidez de datos en una empresa: los 4 principios del Data Mesh
Esa descentralización del dato que propone una gestión basada en Data Mesh no significa prescindir de los data lakes, que siguen siendo necesarios para garantizar el gobierno de los datos. Para posibilitar su aplicación dentro de una plataforma de datos, el Data Mesh establece cuatro principios que a su vez definen su naturaleza:
Orientación específica de dominio
En vez de usar una única capa virtual para administrar fuentes heterogéneas, el Data Mesh usa múltiples dominios, dedicado cada uno de ellos a las necesidades que se requieren específicamente. Es decir, en vez de tomar la información bruta de un único espacio común, un proceso Data Mesh trata previamente la información según su naturaleza y los separa para hacerlos disponibles de forma más rápida y eficaz a quienes lo necesitan.
De esta forma, en un Data Mesh quedarían separados por dominios los datos de ventas, finanzas, RRHH y marketing. Todos ellos tendrían accesibles los datos de unos y otros si así lo requieren, pero de forma instantánea, cada departamento podría acceder a su información y satisfacer necesidades inmediatas de forma mucho más ágil que mediante otro proceso data.
 |
Denominamos dominio en arquitectura data a una colección independiente de clústeres implementables, que a su vez contienen múltiples microservicios que interactúan con usuarios u otros dominios a través de interfaces |
Datos tratados como productos
El dato como centro de todo proceso, ese es el tratamiento que da el Data Mesh a cada información que entra en su flujo. Así, nos encontramos con que cada etapa o cada herramienta dentro de los procesos data mesh, clasifica claramente a los usuarios como productores y como consumidores, y según esta clasificación, el conjunto de datos resultante suele ser ampliamente controlado, que actúa como una API y es accesible para diferentes dominios y el público que lo requiera.
 |
Data Mesh cambia la concepción tradicional de tratar los datos como recursos. Este tratamiento hace que se tienda a su almacenamiento como algo valioso, pero obviando su utilidad. Al ser tratados como producto, una concepción Data Mesh alinea los datos con un proceso de creación y entrega de valor específico, procurando siempre la satisfacción del consumidor. |
Infraestructura de autoservicio
Al igual que no prescinde de elementos como un data lake, Data Mesh no sustituye el trabajo de los ingenieros data, sino que reduce la dependencia que el resto de equipos tiene con estos profesionales a la hora de tratar datos, de forma que los encargados de la ingeniería de datos se pueden dedicar a otras tareas más productivas.
Para ello, Data Mesh facilita una infraestructura que de inicio es creada y mantenida por los data engineers, que ayudan a garantizar operaciones sencillas por parte de los miembros de cada dominio específico sin necesidad de poseer o necesitar conocimientos técnicos sobre el tratamiento de cada dato.
Enfoque bottom-up en el gobierno del dato
Hablamos desde el comienzo de “democratización de los datos”. Dentro de esta prosa es necesario para ello que sean los miembros de cada dominio quienes definan las reglas sobre las políticas, los accesos y el tratamiento que se le dan a los datos que consumen y producen, de forma que no solo tengan la disponibilidad de los datos, sino también su control.
Con este enfoque (denominado bottom-up porque determina el funcionamiento de abajo hacia arriba, es decir, a partir del consumidor final) que hace plenamente partícipe a cada consumidor de datos, se ayuda a garantizar los estándares de calidad del dato al apoyarse la guía creada por ellos con sistemas de verificación y control a lo largo de los flujos de trabajo.
 |
Para saber más sobre las implicaciones técnicas y a nivel de arquitectura que tiene la aplicación de los procesos Data Mesh, consulta nuestro artículo: Data Mesh vs Data Fabric: buscando la mejor arquitectura de datos |
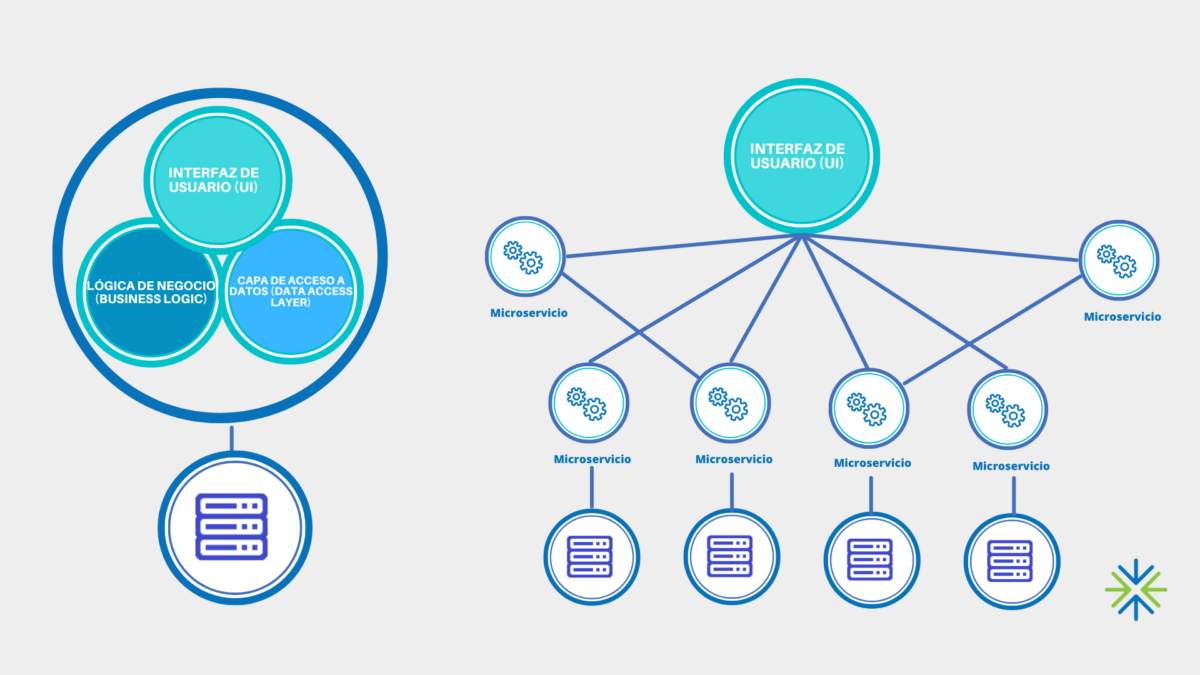
Cómo implementar una arquitectura data mesh: primeros pasos
Data mesh parte de una concepción y de los principios que hemos definido como parte igualitaria. A partir de ahí, cada solución del mercado adapta sus productos a la arquitectura data mesh según la infraestructura que se disponga y las necesidades de cada compañía. Es por ello que la construcción no responde a una hoja de ruta concreta y replicable, aunque sí podemos marcar cuatro pasos como claves a la hora de implementar data mesh:
Mapear los procesos
Como todo proyecto ambicioso de gestión de big data, antes de implementar data mesh es imprescindible que marquemos nuestra hoja de ruta como empresa data. Es decir, los procesos AS IS / TO BE de la plataforma que queremos mejorar con la finalidad de reducir las limitaciones técnicas y que, en el caso de existir, podamos tenerlas resueltas previamente o de forma ágil cuando surjan.
Marcar los dominios de producto
El tratamiento de los datos como producto es parte de la naturaleza del data mesh. Por tanto, un proceso fundamental previo sería definir los dominios: los clústeres en los que se producen los datos (clientes, contactos, productos, proveedores, etc.). De esta forma podremos proporcionarles una dirección y un directorio que permita su procesado.
Transferir los dominios de producto
Con los diferentes dominios localizados, ya se ha llevado a cabo gran parte de la descentralización con la que trabajará la plataforma data mesh. Para que esta descentralización no produzca problemas con la calidad del dato y el hecho de que existan posibles duplicados, no afecte a su tratamiento y gobierno, debemos organizar los dominios y transferirles la propiedad de los datos, creando equipos data dentro de éstos y propietarios que se responsabilicen de su gestión y sepan transmitir reglas adecuadas y apropiadas para evitar caos.
Asegurar el gobierno de datos descentralizado
Para ello, los dominios deben ser autodescriptivos e interoperables. Descentralización no debe ser sinónimo de aislamiento: que cada dominio pueda actuar con independencia solo es posible si se hace bajo unas reglas comunes que permitan la interoperabilidad y el entendimiento entre ellos. Para ello son necesarios glosarios, controles de accesos y unos estándares previos globales para todos.
Con todo ello no estamos modificando toda la estructura, toda la arquitectura data de la empresa, sino implementando una concepción, la del productor como servidor de los datos frente a su anterior papel como simple colector, que nos permitirá un uso más cercano y práctico en el día a día de los datos que permiten el crecimiento como empresa. ¿Sabes por dónde empezar a transformar cómo se interpretan los datos en tu empresa? Nosotros te guiamos en el viaje de ganar competitividad a partir de tus bases.














